
EOF判定の注意点

C言語を勉強してきた中で私の致命的な思い違いシリーズの第三弾です。
今回は、練習で「標準入力からテキストを読み込んで行数をカウントする」という簡単なプログラムを作成した時のことです。標準入力で受けた内容を1バイトづつ読み込み、読み込んだ値が改行コードの場合はカウントアップして行数をカウントする内容のプログラムです。このプログラムの中で遭遇した初歩的なミスの話です。
- 関連記事:コンパイラの最適化によるデメリット
- 関連記事:Linuxで読込中のファイル削除の影響
行数をカウントするプログラム
初めに作成したのが以下のプログラム(lc.exe)になります。
※ちなみに、改行を含まない最終行は考慮してないので厳密な行カウントではなく、改行コードの数をカウントするアバウトな行カウントプログラムになります。
#include<stdio.h>
int main(){
int i = 0;
char c;
c = getchar();
while(c!=EOF){
if(c == 'n'){
i++;
}
c=getchar();
}
printf("line_count = %dn",i);
return 0;
}そして読み込むテキストファイル(text.txt)の中身は下記のようになっています。
apple
bacon
cinamon
dolce
eal
frisk
guitarこのプログラムを以下のように実行すると・・・
$ ./lc.exe < test.txt
line_count = 7と表示され、ちゃんと動いているように思えました。 しかし、文字列は同じだけど別のエンコーディング(UTF-16)で作成されたtext2.txtで試したところ・・・・
$ ./lc.exe < test2.txt
line_count = 0「あれ、おかしい。さっきと中身はまったく同じテキストファイルなのに、
行数カウントが0になっている。エンコーディングが違うだけで、一体なぜ??」
正直なところ、まったく検討がつきませんでした。周りの先輩に聞くと、「バイナリエディタで2つのファイルを見比べてみれば」と言われ、早速確認してみました。
バイナリエディタでファイルを確認する
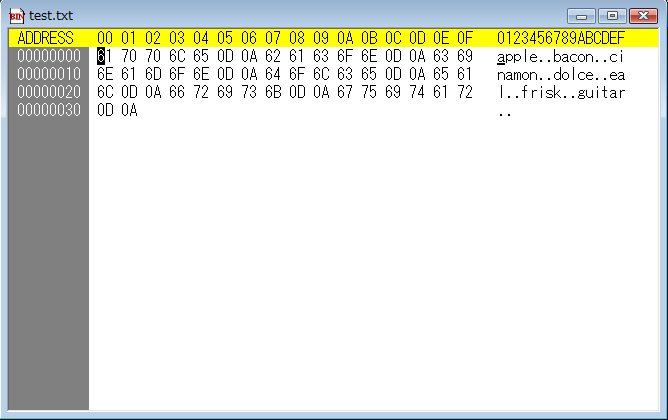
まず1つ目。正確に行数カウントができたtest.txt。
そして次に行数カウントがおかしかったtest2.txt。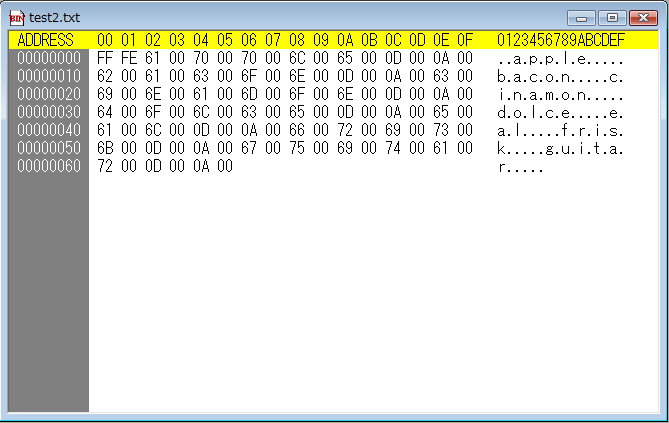
「あれ?test2.txtと中身が違う。test2.txtは1バイト目が「0xFF」ってなっているぞ。」どうやら、test2.txtはBOM付きUTF-16ファイルだからファイルの先頭に「0xFF」が来ていて、何かがおかしくなっているのは分かりました。しかし、それでも勘の悪い私は、何が決定的におかしいのかがわからないのです。そこで、とりあえず冷静に考えてみました。
今回作成したプログラムは改行コードの数で行数をカウントしていて、EOFだったらカウントアップ処理を終えて、行数を標準出力するようにしています。しかし、test2.txtの場合は改行コードは入っているにも関わらず、カウントアップされずに処理を終えています。ということは、改行コードが来る前にEOFがあると判断していることになります。
EOFの正体は?
ここで、新たな疑問に遭遇します。そもそもEOFって何だ?
C言語のEOFが何か知るためにstdio.hを確認してみました。
/* Returned by various functions on end of file condition or error. */
#define EOF (-1)EOFの正体は「-1」でした。では、「EOF」を実際にchar型に代入して16進でprintf表示してみるとどうなるのでしょうか?
#include<stdio.h>
int main(){
char c = EOF;
printf("EOF = %xn",c);
return 0;
}EOF = ffffffffでは、「EOF」と、test2.txtの1バイト目である「0xFF」を、char型に代入して16進でprintf表示して比較してみるとどうでしょうか。
#include<stdio.h>
int main(){
char c = EOF;
char d = 0xFF;
printf("EOF = %xn",c);
printf("0xFF = %xn",d);
return 0;
}EOF = ffffffff
0xFF = ffffffff結果的には両方とも同じになりました。(尚、printfの引数はint型のため、ここでは暗黙の型変換され符号拡張が行なわれ4バイト分表示されています。詳しくはこちらの記事を)確かにこれではtest2.txtの時に行数カウントがおかしくなるわけです。BOMがEOFと同じ値を示すので、すぐに処理が終わってしまいます。よく考えれば当たり前です。
正しいEOF判定の方法
では、この問題を回避するにはどうしたらよいのでしょうか?その答えがEOFを比較している変数の型宣言にありました。C言語の初心者である私は、1文字毎に比較するので、何も気にせずにchar型を指定していました。しかし、そこが大きな間違いだったのです。char型で比較する限り、test2.txtの1文字目「0xFF」と「EOF」を区別することはできないのです。もっと言えば、char型で比較すると「EOF」と同じビットパターンが「EOF」以外にも出現する可能性があるということです。
しかし、char型からint型に変えることによって次のように比較することができるようになります。
#include<stdio.h>
int main(){
int c = EOF;
int d = 0xFF;
printf("EOF = %xn",c);
printf("0xFF = %xn",d);
return 0;
}EOF = ffffffff
0xFF = ffint型で比較することにより「EOF」の場合のみ全てビットが立った状態、つまり「ffffffff」となり、「0xFF」の場合は「000000ff」8ビットのみビットが立った状態で表現でき、区別することができるのです。現に、getchar()の戻り値はちゃんとint型になっています。
なお、UTF-16のテキストをgetchar()で読んで処理するのはそもそも無謀だそうです。C言語の標準ライブラリでは、文字といえば暗黙にASCIIエンコーディングを仮定しているので、ASCII以外のエンコーディングによるテキストファイルをうまく扱うことはできません。私の作ったお手軽ラインカウントは、たまたまUTF-16でもうまく行きましたが、文字列検索処理などになると破綻すると先輩に注意されました。
今回のような間違いは、C言語に対する根本的な知識がないから感覚的な理解に苦しみ、余計にわからなくなっていることがよくわかりました。だから、現在は再度その根本を勉強し直しているところです。C言語ができると言えるようになるまでは、まだまだ長い道のりとなりそうです。
サンプルコードのダウンロード
- ダウンロードには、株式会社シンメトリックの発行するメルマガへの登録が必要です。登録後、ダウンロードURLを登録メールアドレスに送信します。
- サンプルコードは、コンパイルすることなくWindows環境ですぐに動作します。記事の理解に是非お役立てください。
入力したメールアドレスにダウンロードURLをお送りしましたのでご確認ください。