
コンパイラの最適化によるデメリット

以前C言語で、業務とはまったく関係のないお遊びプログラムを作っている時に、不可解な現象に悩まされました。 とある関数の内部で、呼び出し元の情報を書き換えて、関数を抜け出す時に本来の戻り先とは別の戻り先に制御を移すという、ちょっと変な処理を行うものです。 この時は何か目的があってプログラミングをしていたわけではなく、あまり深く考えもせずに作っていたので、最初はプログラムがバグってるのかな?と思っていました。 しかし、何をやってもコンパイル時に最適化オプションを付けた時だけ発生するので、気になり調査しました。
- 関連記事 C言語では signed と unsigned の違いで挙動がこんなにも変わる!
- 関連記事 やっぱり苦労するC言語のNULL文字’¥0′
- 関連記事 C言語でEOFをchar型で比較してまずいのはなぜ?
- 関連記事 C言語、暗黙の型変換と符号拡張の落とし穴
- 関連記事 コンパイラの最適化とは?
ソースコード
問題のプログラムの処理フローは次のようになっています。関数は通常、呼び出した場所にreturnで戻るのですが、このプログラムはreturnをすると次の関数に制御が移るようになっています。

ソースは、以下のコードになります。
- 環境によってはうまく動かない場合もありますが、ご了承ください
- 多少いい加減なコードになっていますが、気にしないでください
環境
OS:Windows Vista SP2(32bit)
CPU:Intel Core2 Duo 2GHz
コンパイラ:Microsoft Visual C++ 9.0 Express
sample.c
#include <stdio.h>
// デバッグメッセージに使用するマクロ
#define DBG_p(s) printf(s)
int func1(int ret);
int func2(void);
// 書き換えた後に、本来のアドレスに戻る時に使用
unsigned int return_address;
// プログラムエントリーポイント
int main(void){
int ret = 0;
DBG_p("in mainn");
ret = func1(1000);
printf("function result = %dn",ret);
DBG_p("out mainn");
return 0;
}
// mainから通常の呼び出され方で呼び出される
// この関数は引数の値をそのままreturnする
int func1(int ret)
{
unsigned int *ebp_addr;
__asm {
// スタック取得
mov ebp_addr, ebp
}
DBG_p(" in func1n");
// リターンアドレスを取得
return_address = ebp_addr[1];
// 指定した関数に書き換える
ebp_addr[1] = (unsigned int)func2;
DBG_p(" out func1n");
// 適当な戻り値を返す
return ret;
}
// func1のreturnの直後に呼び出される
// func1で返した値に1000を足す
int func2(void)
{
unsigned int add_val = 1000;
unsigned int ret_val = 0;
__asm {
// func1の戻り値を加算する
add eax, add_val
mov ret_val, eax
}
DBG_p(" in func2n");
DBG_p(" out func2n");
__asm {
mov eax, ret_val
// 元々の戻り値(func1のリターンアドレス)にジャンプする
mov esp, ebp
pop ebp
jmp return_address
}
}プログラムの詳細は以下のようになっています。
- main関数からfunc1(1000)を呼び出す
- func1で関数の戻り先をfunc2に書き換え、元々の戻り先を保持する
- func1で引数をそのままreturnすると、func2が呼び出される
- func2でfunc1の戻り値に1000を足す
- func2から保持した戻り先(main)に戻る
- mainで結果を表示して終了
まずは、最適化をしない場合の結果です。以下のコマンドでコンパイルします。
cl sample.c
最適化なし結果

次に、最適化オプションを指定した場合の結果です。以下のコマンドでコンパイルします。
cl /Ox sample.c
最適化あり結果 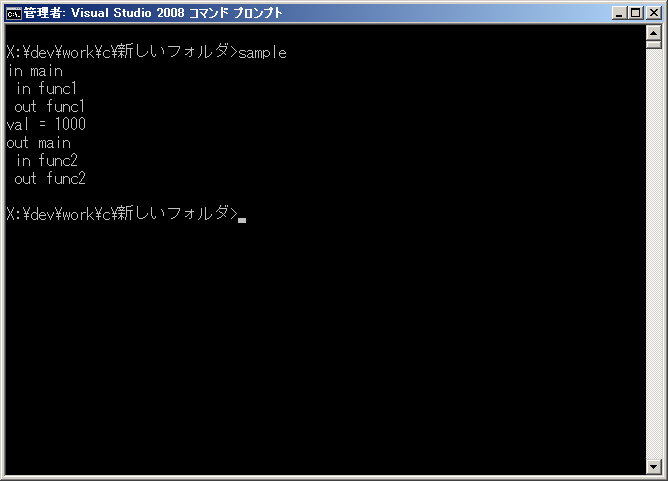
結果を見ると、最適化を行わない場合はfunc1が終わった後にfunc2が呼び出されます。これは想定どおりです。 しかし、最適化を行うとfunc1が終わった後ではなく、mainが終わった後にfunc2が呼び出されます。 実行タイミングがまったく違うので、結果もまったく変わってしまいます。何故こんなことがおきるのでしょうか?
アセンブリ言語のソースを見てみよう
どんな最適化をしたのか、その結果を見てみます。 コンパイルオプションに、アセンブル後のコードを出力させるオプションを追加し、再度コンパイルして見比べてみます。
- 関係ない部分は削ってありますので、そのままでは動きません
- 文字列の出力は最後のprintf以外は消してあります
最適化なしアセンブリコード
_DATA SEGMENT
COMM _return_address:DWORD
$SG2463 DB 'function result = %d', 0aH, 00H
_DATA ENDS
PUBLIC _func1
PUBLIC _main
EXTRN _printf:PROC
_TEXT SEGMENT
_ret$ = -4 ; size = 4
_main PROC
; Line 13
push ebp
mov ebp, esp
push ecx
; Line 14
mov DWORD PTR _ret$[ebp], 0
; Line 18
push 1000 ; 000003e8H
call _func1
add esp, 4
mov DWORD PTR _ret$[ebp], eax
; Line 20
mov eax, DWORD PTR _ret$[ebp]
push eax
push OFFSET $SG2463
call _printf
add esp, 8
; Line 23
xor eax, eax
; Line 24
mov esp, ebp
pop ebp
ret 0
_main ENDP
_TEXT ENDS
PUBLIC _func2
_TEXT SEGMENT
_ebp_addr$ = -4 ; size = 4
_ret$ = 8 ; size = 4
_func1 PROC
; Line 29
push ebp
mov ebp, esp
push ecx
; Line 33
mov DWORD PTR _ebp_addr$[ebp], ebp
; Line 37
mov eax, DWORD PTR _ebp_addr$[ebp]
mov ecx, DWORD PTR [eax+4]
mov DWORD PTR _return_address, ecx
; Line 39
mov edx, DWORD PTR _ebp_addr$[ebp]
mov DWORD PTR [edx+4], OFFSET _func2
; Line 43
mov eax, DWORD PTR _ret$[ebp]
; Line 44
mov esp, ebp
pop ebp
ret 0
_func1 ENDP
_ret_val$ = -8 ; size = 4
_add_val$ = -4 ; size = 4
_func2 PROC
; Line 49
push ebp
mov ebp, esp
sub esp, 8
; Line 50
mov DWORD PTR _add_val$[ebp], 1000 ; 000003e8H
; Line 51
mov DWORD PTR _ret_val$[ebp], 0
; Line 55
add eax, DWORD PTR _add_val$[ebp]
; Line 56
mov DWORD PTR _ret_val$[ebp], eax
; Line 61
mov eax, DWORD PTR _ret_val$[ebp]
; Line 63
mov esp, ebp
; Line 64
pop ebp
; Line 65
jmp DWORD PTR _return_address
; Line 67
mov esp, ebp
pop ebp
ret 0
_func2 ENDP
_TEXT ENDS
END最適化ありアセンブリコード
_DATA SEGMENT
COMM _return_address:DWORD
$SG2509 DB 'function result = %d', 0aH, 00H
_DATA ENDS
PUBLIC _func2
_TEXT SEGMENT
_ret_val$ = -8 ; size = 4
_add_val$ = -4 ; size = 4
_func2 PROC
; Line 49
push ebp
mov ebp, esp
sub esp, 8
; Line 50
mov DWORD PTR _add_val$[ebp], 1000 ; 000003e8H
; Line 51
mov DWORD PTR _ret_val$[ebp], 0
; Line 55
add eax, DWORD PTR _add_val$[ebp]
; Line 56
mov DWORD PTR _ret_val$[ebp], eax
; Line 61
mov eax, DWORD PTR _ret_val$[ebp]
; Line 63
mov esp, ebp
; Line 64
pop ebp
; Line 65
jmp DWORD PTR _return_address
; Line 67
mov esp, ebp
pop ebp
ret 0
_func2 ENDP
_TEXT ENDS
PUBLIC _func1
_TEXT SEGMENT
_ebp_addr$ = -4 ; size = 4
_ret$ = 8 ; size = 4
_func1 PROC
; Line 29
push ebp
mov ebp, esp
push ecx
; Line 33
mov DWORD PTR _ebp_addr$[ebp], ebp
; Line 37
mov eax, DWORD PTR _ebp_addr$[ebp]
mov ecx, DWORD PTR [eax+4]
mov DWORD PTR _return_address, ecx
; Line 39
mov DWORD PTR [eax+4], OFFSET _func2
; Line 43
mov eax, DWORD PTR _ret$[ebp]
; Line 44
mov esp, ebp
pop ebp
ret 0
_func1 ENDP
_TEXT ENDS
PUBLIC _main
EXTRN _printf:PROC
_TEXT SEGMENT
_ebp_addr$2531 = -4 ; size = 4
_main PROC
; Line 13
push ebp
mov ebp, esp
push ecx
; Line 18
mov DWORD PTR _ebp_addr$2531[ebp], ebp
mov eax, DWORD PTR _ebp_addr$2531[ebp]
mov ecx, DWORD PTR [eax+4]
; Line 20
push 1000 ; 000003e8H
mov DWORD PTR _return_address, ecx
push OFFSET $SG2509
mov DWORD PTR [eax+4], OFFSET _func2
call _printf
add esp, 8
; Line 23
mov eax, 9000 ; 00002328H
; Line 24
mov esp, ebp
pop ebp
ret 0
_main ENDP
_TEXT ENDS
ENDごちゃごちゃしてて見難いのですが、注目すべき点は、main関数のコードです。その中でも『; Line 18』と書いてある部分が決定的な違いの部分です。 見やすくする為にmain関数を抜粋しました。
最適化なしmain関数アセンブリコード
_TEXT SEGMENT
_ret$ = -4 ; size = 4
_main PROC
; Line 13
push ebp
mov ebp, esp
push ecx
; Line 14
mov DWORD PTR _ret$[ebp], 0
; Line 18
push 1000 ; 000003e8H
call _func1
add esp, 4
mov DWORD PTR _ret$[ebp], eax
; Line 20
mov eax, DWORD PTR _ret$[ebp]
push eax
push OFFSET $SG2463
call _printf
add esp, 8
; Line 23
xor eax, eax
; Line 24
mov esp, ebp
pop ebp
ret 0
_main ENDP
_TEXT ENDS最適化ありmain関数アセンブリコード
PUBLIC _main
_TEXT SEGMENT
_ebp_addr$2532 = -4 ; size = 4
_main PROC
; Line 13
push ebp
mov ebp, esp
push ecx
; Line 18
mov DWORD PTR _ebp_addr$2532[ebp], ebp
mov eax, DWORD PTR _ebp_addr$2532[ebp]
mov ecx, DWORD PTR [eax+4]
; Line 20
push 1000 ; 000003e8H
mov DWORD PTR _return_address, ecx
push OFFSET $SG2509
mov DWORD PTR [eax+4], OFFSET _func2
call _printf
add esp, 8
; Line 23
mov eax, 9000 ; 00002328H
; Line 24
mov esp, ebp
pop ebp
ret 0
_main ENDP
_TEXT ENDS『; Line 18』見てみると、最適化なしの場合は、引数をスタックに積んでfunc1を呼び出しています。 しかし最適化ありの場合は、ベースポインタを参照してリターンアドレスを取得して・・・っと、まるでfunc1と同じ、と言うよりもfunc1のコードがその場に展開されてます。 そうです。原因は、最適化による関数自体のインライン展開によって、動作が変わってしまっていたのでした。 インライン展開によって処理フローは以下のように変わってしまいました。

インライン展開されることによって、まず取得しているリターンアドレスが変わります。 次にfunc2を呼び出すタイミングが変わるので、func1の戻り値に1000を足しているつもりが、実際にはmainの戻り値に1000を足してしまいます。 結果、全体的に全く想定外の動きになってしまっています。
インライン展開をさせたくない場合は?
コンパイルオプションで、最適化を行わなくする以外に、このプログラムをコンパイルする時に使用したコンパイラMicrosoft Visual C++ 9.0 Expressではコンパイラに対する指示(プラグマ)を用いることで、インライン展開を部分的に抑止することができるようです。 このソースコードの場合は、以下のようなコードに変更します。
#pragma auto_inline( off )
// mainから通常の呼び出され方で呼び出される
// この関数は引数の値をそのままreturnする
int func1(int ret)
{
unsigned int *ebp_addr;
__asm {
// スタック取得
mov ebp_addr, ebp
}
DBG_p(" in func1n");
// リターンアドレスを取得
return_address = ebp_addr[1];
// 指定した関数に書き換える
ebp_addr[1] = (unsigned int)func2;
DBG_p(" out func1n");
// 適当な戻り値を返す
return ret;
}
#pragma auto_inline( on )上記のように、auto_inlineプラグマを指示することで、#pragma auto_inline( off )から、次に#pragma auto_inline( on )が来るまでの間の関数のインライン展開を抑止することができます。 特定の関数のリターンアドレスを意図的に取得したりする場合は、これは必須ですね。
まとめ
コンパイラの最適化の1つにインライン展開という機能があるのは知っていましたが、普段意識していなかったために、今回はアセンブリ言語のソースを見ないと原因がわかりませんでした。 インラインアセンブラでインライン展開してはまずいコードを書いても、コンパイラはそこまで深く判断できずに、展開可能と判断してしまうんですね。
今回の事で、インライン展開の最適化が行われると問題になるケースがあるということを改めて認識し、それを制御する方法があることがわかりました。 ただし、プラグマはコンパイラに対する指示なので、使用するコンパイラによっては使えない場合があります。 使う場合はそれぞれのコンパイラのマニュアルを参照してください。
普段やらないことをやると、当たり前のような事につまずいてしまいます。しかし、何でだろ?と悩んで、調べて一歩一歩解決していくのもプログラミングの醍醐味かなと思います。 こういう普段仕事では組まないような、お遊びプログラムを作るのは楽しいですね。