
NULL文字を含むときはstrcmp/strncmpを使わない

弊社製品ラウンドアバウトが先日正式リリースされた。僕はラウンドアバウトの開発メンバーだったから、やっと完成したという大きな達成感がある。
しかし、その開発期間を思い起こしてみると、C言語特有の問題に直面し、実に苦労すること多かった。ラウンドアバウトはApacheモジュールなので開発言語はC言語となる。C言語で書くと実行速度が速くなるメリットもあるけど、文字列の概念がなかったり、ポインタによるアドレス指定が必要だったりと、プログラミングに注意が必要となる箇所も多い。
その内の一つがラウンドアバウトのキャッシュ機能を開発していた時に発見した不具合だ。ほとんどの画像ファイルは正しくキャッシュされるが、一部のファイルだけキャッシュされないという現象が発生。重要な機能だし、何が何でも解決しなければならない・・・。
あれこれ調べた挙句、特定の画像のみ、NULL文字に起因して発生する現象だと分かった。
C言語の関連記事:
- C言語では signed と unsigned の違いで挙動がこんなにも変わる!
- C言語、暗黙の型変換と符号拡張の落とし穴
- C言語でEOFをchar型で比較してまずいのはなぜ?
- コンパイラの最適化によるデメリット
- コンパイラの最適化とは?
どこにバグがあったのか?
キャッシュ機能は、画像のメタ情報を共有メモリ上に保存するというものだ。キャッシュされたメタ情報は、画像ファイルパスのMD5ハッシュ値をキーとして取り出せるようになっていた。
バグがあったのは、MD5ハッシュ値が一致するかどうかを判断している部分。MD5ハッシュ値は16バイトのバイナリデータのため、本来はmemcmp関数を使って比較を行う必要があったのだ。が、うかつにもstrncmp関数で比較を行っていたのだ。
このバグを生み出した原因として、C言語には言語仕様として文字列の概念を持っていないことが挙げられる。C言語自体では文字列を扱うことができないが、その代わりに、NULL文字で終わるバイナリデータを文字列のように扱うための関数群が用意されている。strncmp関数のようにstrから始まる関数も文字列を扱うことができる関数の一つだ。
また、NULL文字で終わるバイナリデータを文字列として解釈する関数がある一方で、NULL文字を特別に解釈しない関数もある。それがmemcmp関数などのmemから始まる関数だ。
int strncmp(const char *s1, const char *s2, size_t n);
int memcmp(const void *buf1, const void *buf2, size_t n);
そこでstr系関数を使用する場合は文字列、mem系関数を使用する場合はバイナリデータを指定する必要がある。しかし、言語仕様に文字列という概念がないために、コンパイラでのチェックは素通りされてしまう。関数の引数が文字列なのかバイナリデータなのかは、プログラマが注意するより他はない。
しかも厄介なことに、strncmp関数を使用しても、MD5ハッシュ値にNULL文字が含まれていない場合は正しく動作する。しかし、MD5ハッシュ値にNULL文字が含まれていた場合は、MD5ハッシュ値が異なっていた場合でも、一致したという結果を返す場合がある。
C言語における文字列の扱い
C言語には上述した通り、言語仕様上、文字列の概念や配列の長さの概念を持っていない。そこでC言語では、連続する「0x00」以外の文字と、終端を表す「0x00」とで構成されるデータを使用し、「0x00」までの部分を文字列とみなしている。
たとえば、「SYMPLE」という文字列をC言語で取り扱う場合を考える。この場合、「SYMPLE」という文字列の後に続けて次のようにNULL文字を入れたデータを準備する。この合計7バイト(7文字)のデータで「SYMPLE」という文字列を表現できるのだ。
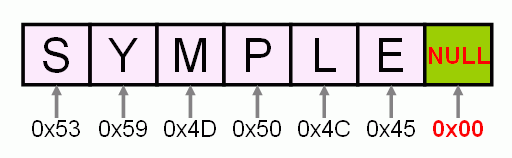
上記の文字列の長さを表示するプログラムをC言語の標準関数strlenを使用して書いてみた。strlen関数は、NULL文字で終わるバイナリデータを文字列と解釈する。
#include <stdio.h>
#include <string.h>
int main() {
char str[7] = {'S','Y','M','P','L','E','¥0'};
printf("%d", strlen(str));
return 0;
}
実行すると次の通り、終端文字までの文字数が表示される。
6
一方、Javaでは言語仕様として文字列の概念を持っている。したがってJavaでは、NULL文字に終端文字のような特別な役割は存在しない。試しに「SYMPLE」の後ろにNULL文字を入れたString型を定義し、長さを取得してみる。
public class NullTest {
public static void main(String[] args) {
String s = "SYMPLE¥0";
System.out.println(s.length());
}
}
このプログラムの実行結果は次のようになる。
7
JavaではNULL文字も1つの文字として取り扱っていることが分かる。
バイナリデータでstrncmpを使うと・・・
strncmp関数の引数には文字列を指定する必要があるが、バイナリデータを指定すると問題が発生する。
strncmp関数は2つの文字列を比較し、先頭から指定した文字数までが一致していれば0を返すという関数だ。ただし途中にNULL文字が含まれていれば、指定した文字数まで達していなくても、その前の部分のみで比較が行われる。str系関数の特徴だ。
MD5ダイジェストの比較を行う際、比較する文字数としてダイジェストの長さ16を第3引数に指定していた。ダイジェストにNULL文字が含まれていない場合は、16バイトでの比較が行われる。だが、ダイジェストにNULL文字が含まれていた場合は、16バイトでの比較が行われない。
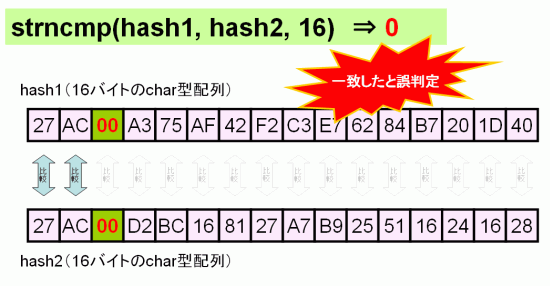
たとえば、先頭3バイトのみが一致し、以降13バイトが異なる2つのハッシュ値を比較する場合を考えてみる。ハッシュ値にNULL文字(0x00)が含まれていない場合は、次のように16バイト分の比較がおこなわれるため、正しい結果が返される。

しかし、ハッシュ値の3バイト目がNULL文字(0x00)の場合、次のようにNULL文字までの先頭2バイトだけでの比較が行われる。したがって、ハッシュ値は一致していないのにstrncmpの戻り値は一致したことを表す0となってしまう。
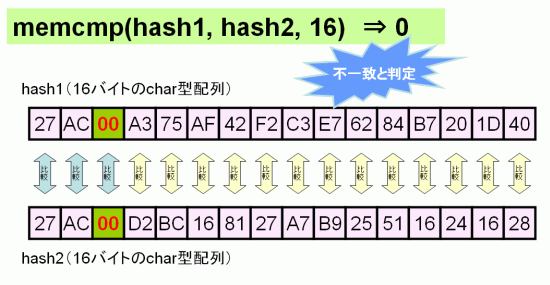
NULL文字を終端文字を解釈することなく、指定したバイト数だけ比較を行うには、memcmp関数を使用する。この関数では単純に指定したバイト数分だけ比較を行う。途中にNULL文字が入っていた場合でも、指定されたバイト数での比較が行なわれる。
バイナリデータか文字列かをどのように区別するか?
C言語では、Javaと比べると型付けが強くはない。Javaでは文字列とバイナリ配列は明確に型が異なるため、誤った型を関数の引数に指定すると、コンパイラがエラーとして検出する。C言語では文字列とバイナリデータを明確に区別することができない。
したがってC言語では、扱うデータがバイナリデータなのか、文字列なのかをプログラマが強く意識してコーディングする必要がある。
関数や変数の誤使用を未然に防ぐための方法はいくつか存在する。いずれも完璧な方法ではないが、型に対する意識が向上するため、ケアレスミスは防ぎやすくなる。
変数のネーミングルール
いわゆるハンガリアン記法(現在ではアプリケーション・ハンガリアン記法と呼ばれる)を使用するというもの。たとえば、バイナリデータを表す変数名はすべて”bin_”から始まるようにし、文字列を表す変数名はすべて”txt_”から始めるようにする。
// バイナリ型
char bin_hash1[16];
char bin_hash2[16];
...
if (memcmp(bin_hash1, bin_hash2, 16) == 0) {
...
}
// 文字列
char txt_hash1[33];
char txt_hash2[33];
...
if (strcmp(txt_hash1, txt_hash2) == 0) {
...
}
こうしておくことで、変数の名前からの変数の用途や型を類推しやすくなる。
バイナリ型はunsigned char型を使用する
文字列はchar型、バイナリ型はunsigned char型を使用する。Apacheのソースコードを見ると、ネーミングルールは決めずにこのルールに則っているようだ。
// バイナリ型
unsigned char hash1[16];
unsigned char hash2[16];
...
if (memcmp(hash1, hash2, 16) == 0) {
...
}
// 文字列
char hash1[33];
char hash2[33];
...
if (strcmp(hash1, hash2) == 0) {
...
}
バイト型を定義する
byte型をtypedefで定義する方法。変数定義部分に関しては、ソースコードの可読性がいい。
typedef unsigned char byte;
// バイナリ型
byte hash1[16];
byte hash2[16];
...
if (memcmp(hash1, hash2, 16) == 0) {
...
}
// 文字列
char hash1[33];
char hash2[33];
...
if (strcmp(hash1, hash2) == 0) {
...
}
独自関数を使用する
memcmpやstrcmpを直接使用せず、独自関数を経由して使用する。この方法は関数を使用する際に型の意識を促す。
// ユーティリティ
int binary_compare(const unsigned char* b1, const unsigned char* b2,
size_t len) {
return memcmp(b1, b2, len);
}
int text_compare(const char* t1, const char* t2) {
return strcmp(t1, t2);
}
// バイナリ型
unsigned char hash1[16];
unsigned char hash2[16];
...
if (binary_compare(hash1, hash2, 16) == 0) {
...
}
// 文字列
char hash1[33];
char hash2[33];
...
if (text_compare(hash1, hash2) == 0) {
...
}
実際、このような共通ライブラリも作成していたのだが、用意していたのは文字列用の関数だけだった。バイナリデータを扱う機会が少なかったため、直接memcmpなどを呼び出していた。
文字列構造体、バイナリ配列構造体を定義する
char配列を直接使用せず、文字列やバイナリ配列を表す構造体を経由する方法。この方法は最も安全だが他の関数を使用する際に変換が必要となる場合があるため、型変換に苦労する可能性もある。
typedef struct bytearray_s {
unsigned char* buff;
size_t len;
} bytearray_t;
typedef struct string_s {
char* buff;
size_t len;
} string_t;
// ユーティリティ
bytearray_t* bytearray_create(const unsigned char* b, size_t len) {
bytearray_t* bytearray = (bytearray_t*)mcalloc(sizeof(bytearray_t));
bytearray->buff = (unsigned char*)mcalloc(sizeof(unsigned char) * len);
memcpy(bytearray->buff, b, len);
bytearray->len = len;
return bytearray;
}
int bytearray_compare(const bytearray_t* b1, const bytearray_t* b2) {
return memcmp(b1->buff, b2->buff, b1->len);
}
// バイナリ型
bytearray_t* hash1;
bytearray_t* hash2;
...
if (bytearray_compare(hash1, hash2) == 0) {
...
}
// 文字列
string_t* hash1;
string_t* hash2;
...
if (string_compare(hash1, hash2) == 0) {
...
}
Javaの場合は・・・
Javaではバイナリデータと文字列とで明確に型が異なるため、コンパイラによる型チェックが行われる。バイナリデータはbyte型、文字列はStringクラスだ。
2つの文字列やバイナリデータを比較する方法としては、バイナリデータなら Arrays#equals(byte[], byte[]) メソッド、文字列なら String#equals(Object) が用意されている。byte型とStringクラスは互換性のない型のため、Arrays#equalsにString型を指定するとコンパイルエラーとなる。
Javaでは、NULL文字はあくまで1つの文字として扱われる。文字列の終端という目的でNULL文字を使用することはない。
Javaはこの辺りが実によく設計されていると思う。Javaにおける配列は、配列のエントリーとは別に配列の長さの概念を言語レベルで持っている。文字の配列である文字列は、終端文字を使わなくても配列の長さから終端を判別できる。したがってNULL文字に文字列の終端という特別な意味を持たせる必要がなくなっているのだ。
まとめ
C言語は他の言語にはない落とし穴が多い。だからこそ、コーディングルールの徹底や共通化などの創意工夫したプログラミングが必要だ。
C言語の関連記事: